European Union Publications Office Cellar Project
An Interactive Overview of Key Resources and Demonstrations
Cellar Architecture Deep Dive
What is Cellar?

Cellar is the common data repository of the Publications Office of the European Union. Digital publications and metadata are stored in and disseminated via Cellar, in order to be used by humans and machines. Aiming to transparently serve users, Cellar stores multilingual publications and metadata, it is open to all EU citizens and provides machine-readable data.
Project Scope & Objectives
The Publications Office aims to provide a unified, central repository, Cellar, to store and disseminate all EU publications and data. Key objectives include:
- Serving as the authoritative source for legal acts, case-law, and official journals.
- Storing metadata based on the FRBR model, ontologies, thesauri, and controlled vocabularies.
- Promoting transparency and knowledge diffusion through open access based on Semantic Web principles.
- Providing robust, public-facing query capabilities via a high-performance SPARQL endpoint.
The Global Picture
Cellar receives publications and their associated metadata based on the Metadata Encoding Transmission Standard (METS). It stores and disseminates digital publications and metadata for various EU services.

Triple Store Architecture Overview
The Cellar infrastructure is built around high-availability Virtuoso installations.
- CELLAR Virtuoso SPARQL endpoint: The primary public access point for querying the Cellar knowledge graph.
Visual SPARQL Query Editor
The Publications Office provides an Advanced SPARQL Query Editor for a user-friendly way to construct and execute queries against the Cellar knowledge graph.
TED Open Data Service
The public procurement data collected by the Publications Office is available as Linked Open Data in the TED Open Data Service. This tool allows you to explore and download TED Open Data using SPARQL queries. You can use it to compose your queries, test them, and customise the dataset that you want to retrieve. You can then use these queries to retrieve live data directly into your applications.
This application is developed by the Publications Office of the EU and is available as open source on GitHub.
Accessing Cellar Data via REST API
How to request a publication?
A publication can be requested via a RESTful interface, using as a criterion its linguistic version and format.
URL to request:
http://publications.europa.eu/resource/{ps-name}/{ps-id}?language={dec-lang}Parameters:
{ps-name}: A valid production system name.{ps-id}: A valid production system id, identifying a work.
HTTP Headers:
Accept:{mime-type}: e.g., application/pdf, application/msword, application/rdf+xml, etc.Accept-Language:{acc-lang}: A 3-char ISO_639-3 language code.Accept-Max-Cs-Size:{size}: Max content stream size in bytes.
How to request a collection of publications?
A collection of publications can be requested via a RESTful interface.
URL to request:
http://publications.europa.eu/resource/{ps-name}/{ps-id}?language={dec-lang}Parameters:
{ps-name}: A valid production system name.{ps-id}: A valid production system id, identifying a work.
HTTP Headers:
Accept:{mime-type}: e.g., application/list;mtype={manifestation-type} or application/zip;mtype={manifestation-type}.Accept-Language:{acc-lang}: A 3-char ISO_639-3 language code.
By The Numbers
- 44M files stored
- 40 TB of data
- 1B triples in knowledge graph
- 95M resources
- 20M average daily requests
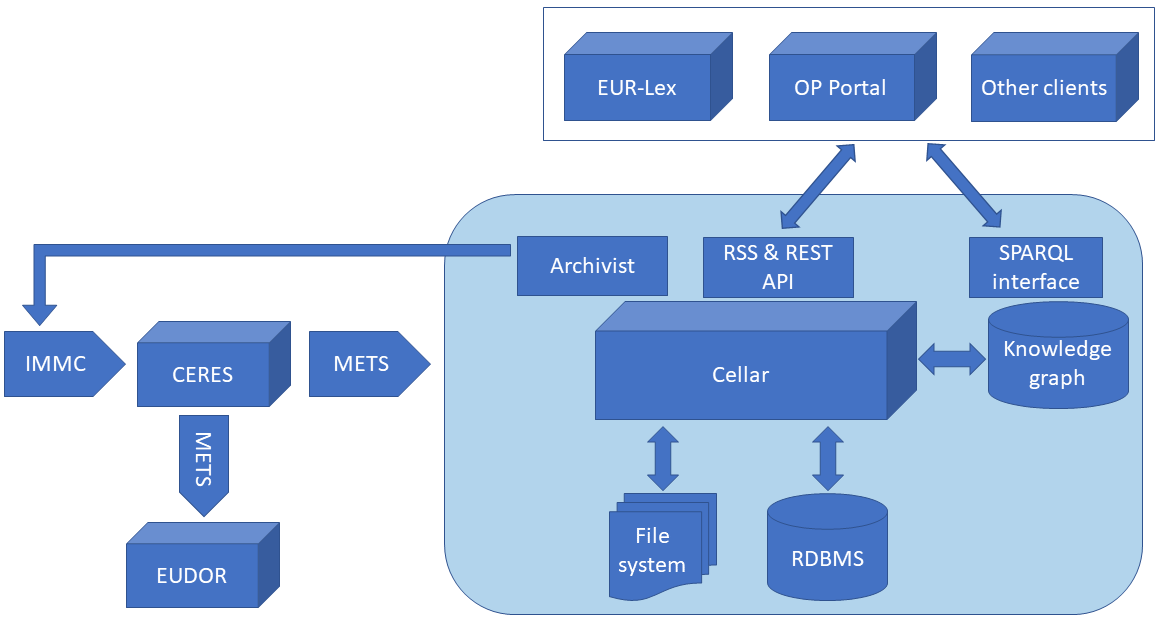
Ecosystem & Workflow
Cellar is part of a wider ecosystem that includes several key components handling the publication lifecycle.
-
1
IMMC Package Creation
IMMCbuilder creates an IMMC package containing digital publications and metadata.
-
2
Reception and Validation
CERES receives and validates IMMC packages, generating METS packages for Cellar.
-
3
Storage in Cellar
Digital content is stored in Cellar's file system, RDBMS, and knowledge graph.
-
4
Dissemination
Dissemination occurs via EUR-Lex and the OP Portal using RSS, REST API, and SPARQL interfaces.
-
5
Archiving
Archivist sends publications and metadata to EUDOR, the long-term archive.
Data Sources & Workload Estimates
| Source | Datasets | Triples (est.) | Growth |
|---|---|---|---|
| EU Legal Content | EU Law (EUR-Lex), Treaties, Case Law, International Agreements | Large-scale | Continuous growth with new legislation and case law |
| Publications | Official Journals, General Publications, Research Papers | Large-scale | Stable and continuous |
| Metadata & Vocabularies | FRBR-based metadata, EuroVoc, Named Authority Lists (NALs), Thesauri | Medium-scale | Ongoing updates and enrichments |
| Total | — | Billions+ (inferred from system scale) | Sustained growth across all data types |
Further details are available in the Cellar Stats Comparison and KGC Presentation.
Use Case Summary
| Data Type | Description | Access |
|---|---|---|
| Public Legal Data | Querying for specific legal acts, their status, entry-into-force dates, and inter-relations. | SPARQL Endpoint |
| Bibliographic Data | Retrieving EU publications and documents based on the WEMI (Work, Expression, Manifestation, Item) model. | SPARQL Endpoint |
| Controlled Vocabularies | Accessing and navigating concepts from NALs like EuroVoc, corporate bodies, and subject matter directories. | SPARQL Endpoint |
| Entity Data | Retrieving structured information on individuals and organizations from sources like the EU Whoiswho. | SPARQL Endpoint |
Clustering Strategy
| Instance | Reasoning |
|---|---|
| Production | To handle the high volume of public queries and data serving requirements for the live Cellar service. Ensures high availability and performance. |
| Non-Production | For development, testing, data loading, and quality assurance without impacting the production environment. |
Cello (OPAL-based Agent/Assistant Prototype) Demos
Cello is an OPAL-based prototype that demonstrates an AI Agent/Assistant developed in natural language using markdown, with loose coupling between a selected LLM and the Cellar SPARQL endpoint.
Demo 1: Explicitly Executed Requests



Demo 2: AI-Generated Queries
In this demo, we allow the OpenLink AI Layer (OPAL) to generate its own queries.


